
The upcoming Volta architecture should launch along next-generation supercomputers dubbed Summit and Sierra. Although few details surrounding Volta GPU are known at the moment, NextPlatform did an analysis revealing the Volta GPU are incredibly fast, offering tons of computing power.

Pascall GP100 GPU was announced as the largest ship endeavor in history, and indeed the chip is incredibly fast, a real achievement for 2016. It provides lots of power for the HPC and data center market. The chip is also used in NVidia’s DGX SaturnV supercomputer designed to help the company construct next-gen GPUs (the tech is known as GPUs Designing GPUs).
After Pascal, it will be hard for NVidia to offer a chip offering the same scale of improvements, but the Volta is shaping up to be even more impressive than Pascal. First details regarding Volta were showed during 2015 when NVidia presented a chart showing estimated performance of its upcoming GPU architectures. According to the chart, Volta should offer twice the compute power and twice the memory capacity compared to Pascal, with higher efficiency and faster bandwidth.
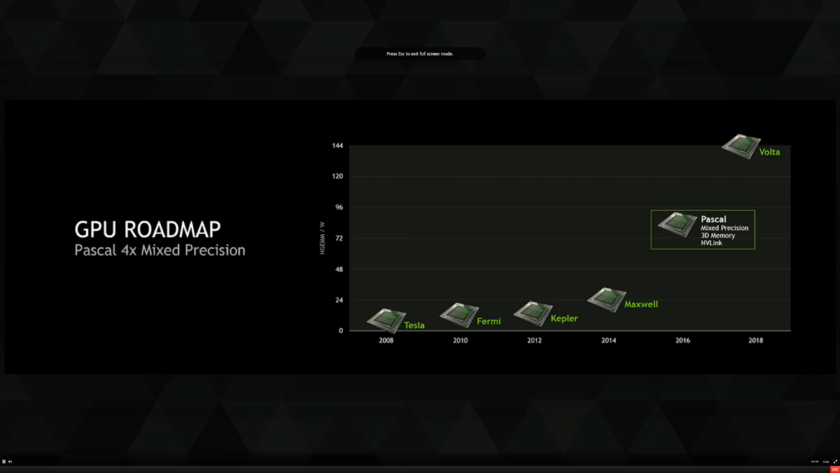
Since Pascal brought almost every specs NVidia promised, expect 32 GB capacity (which was removed due to the HBM production issues) it seems the upcoming Volta architecture will feature full 32 GB memory capacity.
Details about the Summit supercomputer revealed that HPC (High-Performance Computing) market will gain big with the introduction of Volta architecture. Firstly, the Summit supercomputer offers five to ten times higher application performance when compared to the Titan supercomputer. Titan supercomputer features Kepler (GK110 GPU) architecture, is made out of 18,688 nodes rated at 1.4 TF per node. The Summit features around 4,600 nodes with a rated compute the output of over 40 TF per node, which is a quantum leap in performance per node.
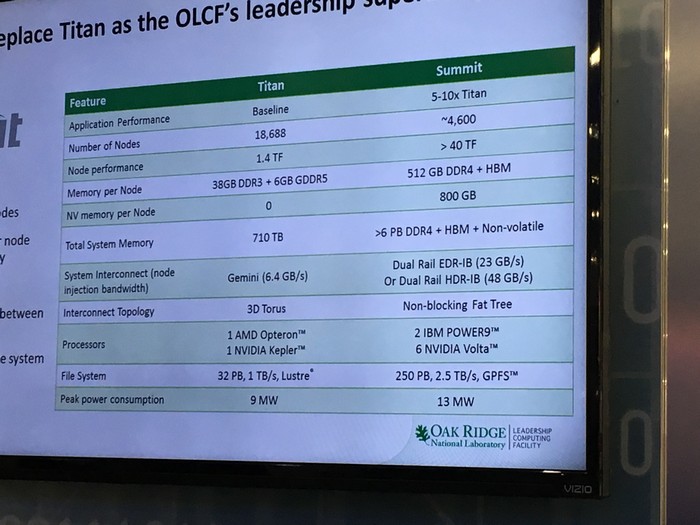
Each node packs 512 GB of DDR4 and HBM memory, along with 800 GB of NV (Non-Volatile) memory per node (Titan features “just” 38 GB of DDR3 and 6 GB GDDR5 per node). When taking into account all memory types per one node, the Titan features 710 TB in total while the Summit packs more than 6 Petabytes of memory. Each node will host 2 IBM Power9 CPUs and 6 NVIDIA Volta V100 GPUs along with a full integration of NVidia’s NVLINK2 interconnect between nodes. The supercomputer will consume 13 MW of power, a small increase over the Titan (9 MW). Impressive if we look at performance gains.
NVidia Volta GV100 GPUs will deliver SGEMM (Single precision floating General Matrix Multiply) of 72 GFLOPS/Watt compared, according to NVidia; for comparison, Pascal GD100 is able to deliver 42 GFLOPs/Watt. This means that a Volta GP100 GPU can deliver 9.5 TFLOPs of double precision performance (with 300 TPD rating), almost doubling the numbers of the GP100.
Since the barrier per node is 40 TF (and six 300W Volta GPU can deliver more than 57 TFLOPs) it is expected for the TDP to be 200W meaning that the six GPUs will deliver 38.2 GSLOPs/Watt. The final dual-precision compute power of Volta V100 GPU may go to 8 or 9 TFLOPs, a feat worthy of respect. Since the slides from GTC 2015 show that Volta should have a memory bandwidth of around 900 GB/s, it is possible for the bandwidth to go over 1 TB/s, if the Volta GV100 ships with 32 GB of HBM2 memory.

The HBM memory is a great memory architecture, as Stephen W.Keckler (Senior Director of GPU Architecture) stated; but, the HBM working at 1.2 TB/s (a bit higher than we expect) is adding 60W to the TDP of a standard GPU. AMD used HBM1 on Fiji chips, and it added 25W to the TDP. The power problems are increasing with higher bandwidth. A GPU with 2.5 TB/s will increase TPD for 120W, and with a bandwidth of 3 TB/s TDP will increase for 160W. This is too much just for the memory alone.
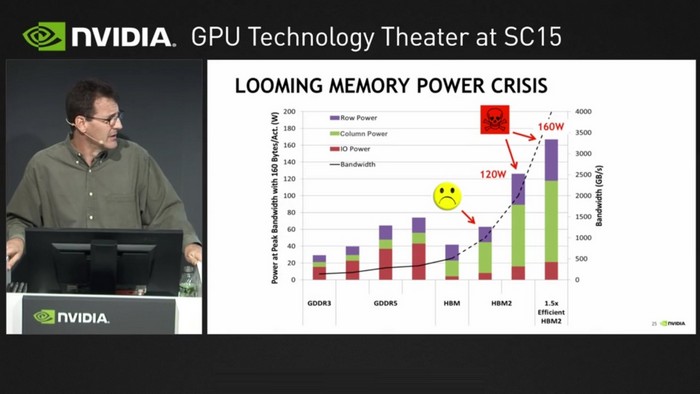
Since HBM is just devouring power, NVidia can use it with Volta, but with bandwidth increase, the company will either have to limit the power consumed by the HBM or to try to make a completely new memory architecture that isn’t so power hungry.
The Summit supercomputer should cross the 250 Petaflops mark, becoming the top performing machine in the world. It should be built in late 2017-early 2018 for the US Department of Energy for its Oak Ridge National Laboratory.