
Computer-generated speech has been around for a while now. You can easily turn a piece of text into speech. However, the resulting speech is always very mechanical. It can be easily distinguished from ordinary human speech. Now, Google with Alphabet’s DeepMind has a system, that is getting really good at sounding like humans.
The company revealed its new artificial neural network system, called WaveNet, in a blog post. This could mean in future you could just type and your smartphone or camera will be able to talk for you. Or your tablet will be able to read your emails to you in a human voice. There are multiple unexplored possibilities here.

Google’s DeepMind is responsible for creating artificial intelligence systems that can play Atari classics, or even complex games like Go, just like humans. Now, DeepMind researchers have developed a new technique to produce speech and even music that sounds like the real thing.
Google’s WaveNet simulates the sound of speech at as low a level as possible – one sample at a time. It creates the sound waveform from scratch at 16,000 samples per second. The artificial neural network learns from raw audio files and then produces digital sound waves resembling those produced by the human voice. The company claims that WaveNet outperforms existing text-to-speech technologies by 50 percent.
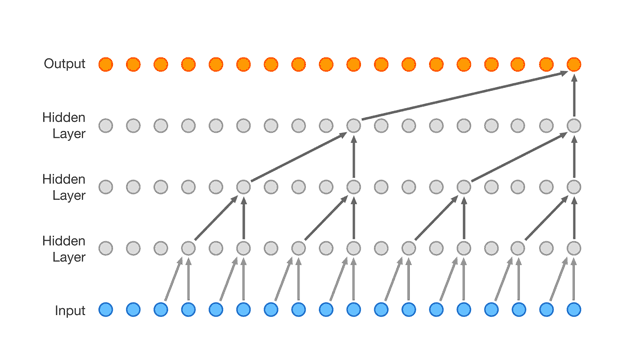
A ton of ordinary recorded speech is entered into an artificial neural network. This creates a complex set of rules that determine which tones follow other tones in every common context of the speech. Hence, in this process, each sample is not just determined by the sample before it, but the thousands of samples that came before it. All samples are fed into the neural network’s algorithm. Now, the WaveNet knows that certain tones or samples will almost always follow each other, while others won’t.
If data from a single speaker is fed into WaveNet, the resulting speech will resemble that speaker. This happens, since all the information the network has about speech comes from this voice. However, if speech from multiple speakers is fed, the system will cancel out idiosyncrasies of one person’s voice with other. In this case, the result will be a more natural, smoother sounding speech. Here’s a sample:
https://soundcloud.com/discovermag-1/google-deepminds-wavenet-speech-generation-ai
WaveNet can also generate non-speech sounds like breaths and mouth movements. It can even model music. Here it is mimicking a piano:
https://soundcloud.com/discovermag-1/wavenet-artificial-intelligence-playing-piano
The system still has certain shortcomings which might be corrected once diverse speakers patterns are introduced into the system. As of now, WaveNet can’t read text straight out just yet. A different system is used to translate written words into audio precursors, like a computer-readable phonetic spelling.
Amazing thing is, since WaveNet works with raw audio waveforms, it can model any voice, in any language. However, since WaveNet requires huge computing power to simulate complex patterns at an extremely low level, it is quite far from becoming an app in your smartphone.
For more technical details and through results, you can read the DeepMind team’s paper here.